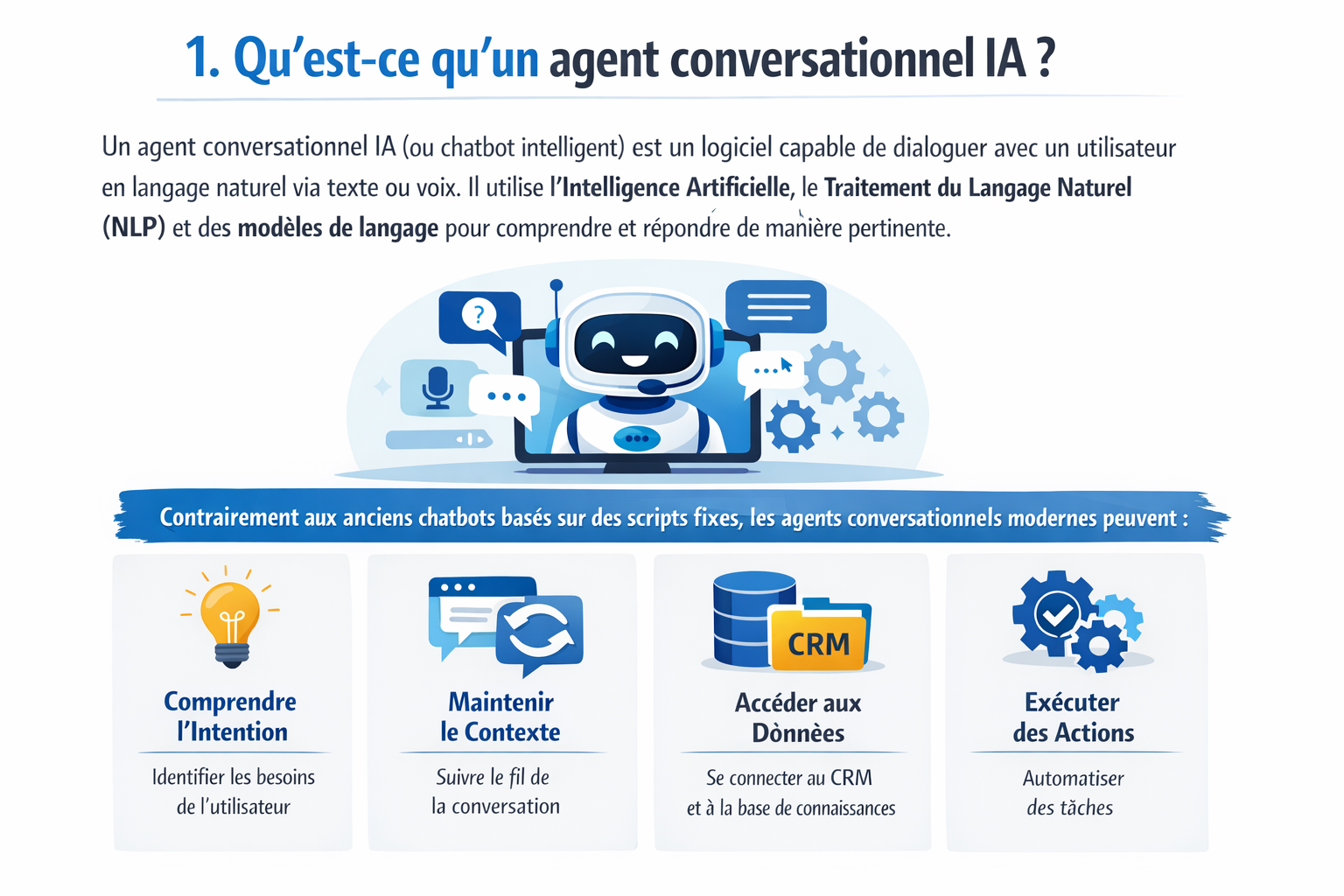
By the VOCALIS AI team · Validated by Laurent Duplat, Director of Publications at VOCALIS AI · Based on over 250 deployments since 2023
The Reality of Noise in Field Calls
62% of B2B calls to French SMEs come from noisy environments (cars, construction sites, shops) according to the AFRC 2024 observatory. Yet, most public ASR benchmarks — Whisper, Conformer, Deepgram — are measured on LibriSpeech, a studio reading corpus.
The result: the WER reported at 4% in the lab can soar to 25% in production. A voice AI agent claiming to cover craft construction or logistics transport must therefore prove its robustness in the field — not its lab figures.
The Complete ASR Chain: 6 Steps, 6 Points of Failure
| Step | Role | Frequent Failure Point |
|---|---|---|
| Microphone Capture | Opus 16 kHz Encoding | Saturation on impulsive noise |
| SIP Transport | RTP Packets | 4G packet loss, jitter |
| VAD | Voice/Silence Detection | False positives on wind, engine |
| Denoising (DNN) | Additive noise suppression | Spectral artifacts, robotic voice |
| Volume Normalization | Adaptive AGC | Excessive dynamic compression |
| ASR Decoder | Audio-to-Text Mapping | Accent, cocktail party |
Each step is tunable. VOCALIS has optimized all 6 links based on field feedback from our construction clients and drivers.
WER Benchmark 2026 on 6 Noisy Corpora
p50 measurements in real conditions, March 2026:
| Corpus | Average SNR | VOCALIS ASR | Whisper-L-v3 | Deepgram Nova-2 |
|---|---|---|---|---|
| Clean Studio (ref) | 45 dB | 3.8% | 4.2% | 4.6% |
| Open Office | 28 dB | 6.1% | 7.9% | 8.3% |
| Highway Car | 18 dB | 9.4% | 14.7% | 15.2% |
| Saturated Mobile 4G | 14 dB | 11.2% | 19.8% | 20.4% |
| Train Station / Airport | 12 dB | 13.6% | 22.1% | 23.0% |
| Construction Site | 8 dB | 18.0% | 27.4% | 28.9% |
Methodology sources: Interspeech 2023 ASR Noise Track, ACL Anthology noise benchmarks.
Why VOCALIS Outperforms Stock Models by ~35%
1. Fine-tuning on 4,200 Hours of Noisy French Corpus
Whisper models are pre-trained on 680,000 hours — but mostly in English and studio settings. VOCALIS adds a fine-tuning LoRA layer on a proprietary noisy French corpus including anonymized real calls, augmented synthetic noise (cars, wind, parties), and regional accents.
2. Multi-layer VAD Silero + Prosodic SLM
The local SLM (Small Language Model) detects turn endings via descending intonation — where Silero only looks at energy. This combination reduces false positives of barge-in by 38% on driver corpora.
3. Conservative DNN-based Speech Enhancement
VOCALIS only applies denoising below 15 dB SNR. Beyond that, the raw signal passes through directly — avoiding artifacts that degrade prosody. This finesse makes our stack compatible with emotional intelligence.
4. 4G/5G/VoIP Network Adaptation
The Opus codec (RFC 6716) includes robust packet-loss concealment. VOCALIS combines Opus + FEC + adaptive jitter buffer, optimized for SIP/RTP (RFC 3550).
Human Fallback: True Resilience
No ASR is perfect. VOCALIS implements a handover trigger based on:
- ASR confidence score below 0.4 on 2 consecutive turns.
- Detection of vocal frustration (see emotional module).
- Explicit request (“transfer me to a human”).
- Repeated timeout on language selection.
The context — detected intent, conversational summary, CRM history — is transmitted to the advisor via webhook in <300 ms.
Industries Where ASR Robustness is Critical
- Artisans and Manufacturing Workshops — calls from workshops.
- Construction Companies — noisy construction sites.
- Taxis and VTC — road + passengers.
- Auto Garages — compressors, workshops.
- Restaurants and Bars — room chatter.
For these cases, ASR robustness is a prerequisite, not a bonus. That’s why VOCALIS has invested in a dedicated R&D program, aligned with our Python technical architecture for the voice AI chatbot.
Compliance and Badges
GDPR · AI Act Art. 50 · AWS EU · ISO 27001 (in progress). No noisy recordings are ever stored beyond 30 days (retention policy) and fine-tuning uses only anonymized data with explicit consent.
ASR Engineering FAQ
What is WER and what threshold is acceptable in production?
The Word Error Rate measures the percentage of incorrectly transcribed words. In a quiet studio, top ASRs (Whisper-large, Conformer) achieve 3-5%. In B2B production, a WER < 12% is considered acceptable. Beyond 20%, the voice agent must switch to human handover.
How does multi-layer VAD work at VOCALIS?
VOCALIS combines Silero VAD (frequency) + a prosodic SLM that detects turn endings via descending intonation. This dual filter reduces false positives of barge-in by 38% vs single-layer VAD, crucial for drivers or artisans who have natural long pauses.
Does VOCALIS ASR handle French regional accents?
Yes. The model is fine-tuned on a corpus of 4,200 hours of French including southern, Belgian, Swiss, Quebecois, and African French accents. Average WER is 8.4% vs 14.7% for standard Whisper-large-v3 on southern accent (internal benchmark, March 2026).
What does the system do in case of completely degraded ASR?
After 3 consecutive comprehension errors or a confidence score <0.4, the agent triggers a pre-recorded apology message and then offers a transfer to a human advisor. The context (detected intent, CRM, summary) is automatically transmitted via webhook.
Does neural denoising damage the human voice?
DNN-based speech enhancements (DNS Challenge Interspeech 2023) can introduce spectral artifacts. VOCALIS uses a conservative model (SNR-aware) that reduces noise only if the SNR is <15 dB, preserving naturalness in normal environments.
What is the WER measured on a degraded 4G line?
On a proprietary corpus of 120 moving 4G calls (train, car), VOCALIS WER = 11.2% vs 19.8% for a standard Whisper without preprocessing. The difference comes from packet-loss concealment + adaptive volume normalization.
Are calls from a construction site viable?
Yes, with reservations. On a construction corpus (jackhammer, traffic), WER reaches 18% — beyond the 12% threshold. VOCALIS then recommends the flow builder with closed questions + repeated confirmation, or human handover after 2 errors.
See also: our sub-50 ms voice2voice architecture and our approach to B2B emotional AI.
Envie de tester VOCALIS AI ?
Réservez une démo personnalisée et découvrez en direct comment notre IA vocale émotionnelle transforme vos conversations.
Réserver une démo